Interactions in Information Spread
Since the invention of writing 5000 years ago, textual information data flows got generated at an increasing pace. The generation rate has been greatly influenced by technical innovations: clay tablets, papyrus, paper, press, and more recently the Internet. At the same time, new methods designed to handle and archive this growing information flows emerged (in the same order as before): clay archives (Nippur, Mari), early libraries (Alexandria, Rome’s Tabularia, Athens’ Metroon), religious scriptoriums (abbeys, monasteries), modern libraries and, more recently, machine learning. Each of these aims at easing information retrieval.
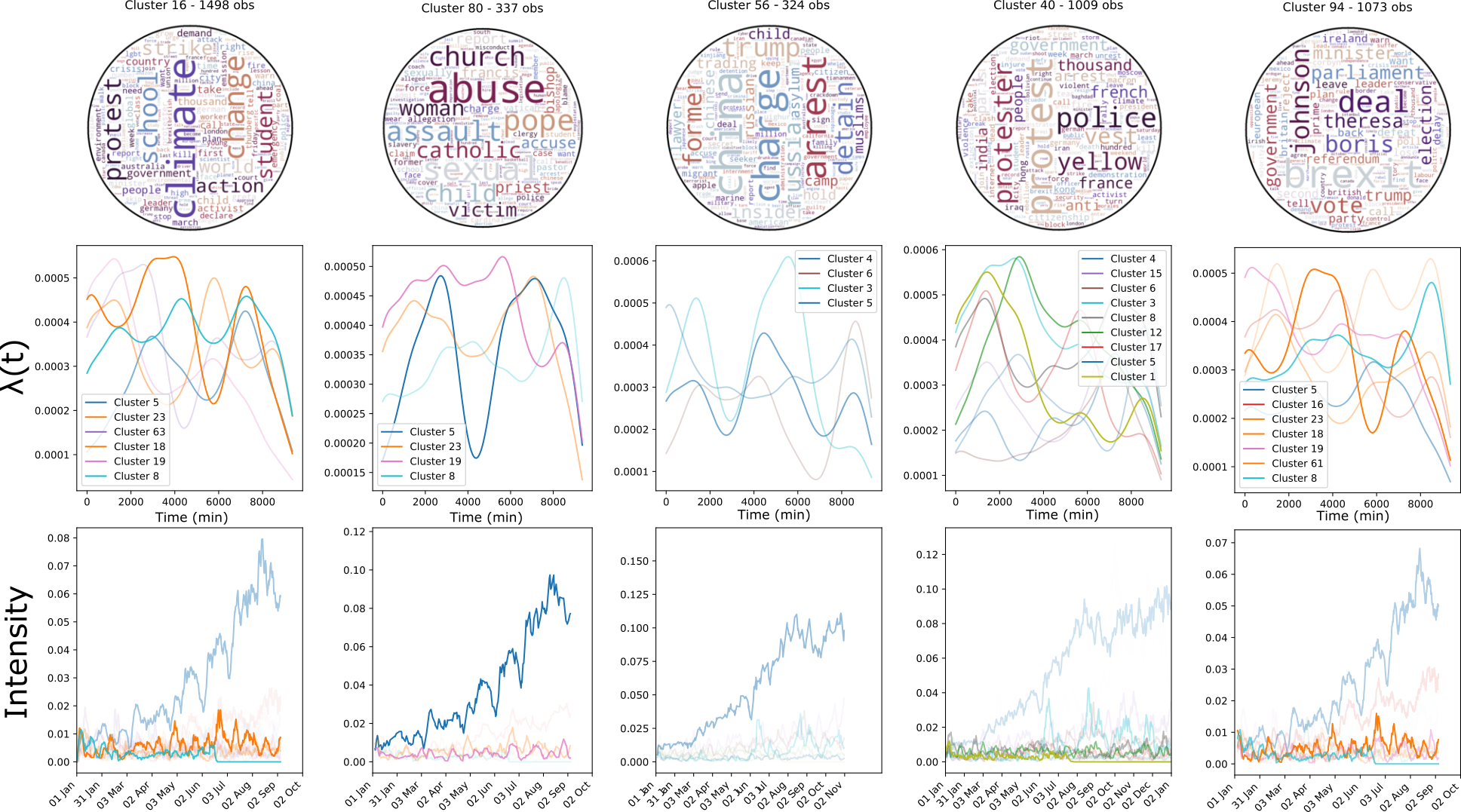
Nowadays, archiving is not enough anymore. The quantity of data that gets generated requires new tools for information retrieval. In particular, automatically generating summaries of large data flows became a priority. Instead of referencing every single data piece as in traditional archival techniques, a more relevant approach consists in understanding the global ideas conveyed in data flows. To spot such global trends, a fine comprehension of the underlying data generation mechanisms is required.
In the rich literature tackling this problem, the question of information interaction remains nearly unexplored. Explicitly, does previously generated data influence on ulterior data generation processes. In this manuscript, we develop a panel of methods that explores this specific aspect of data generation.
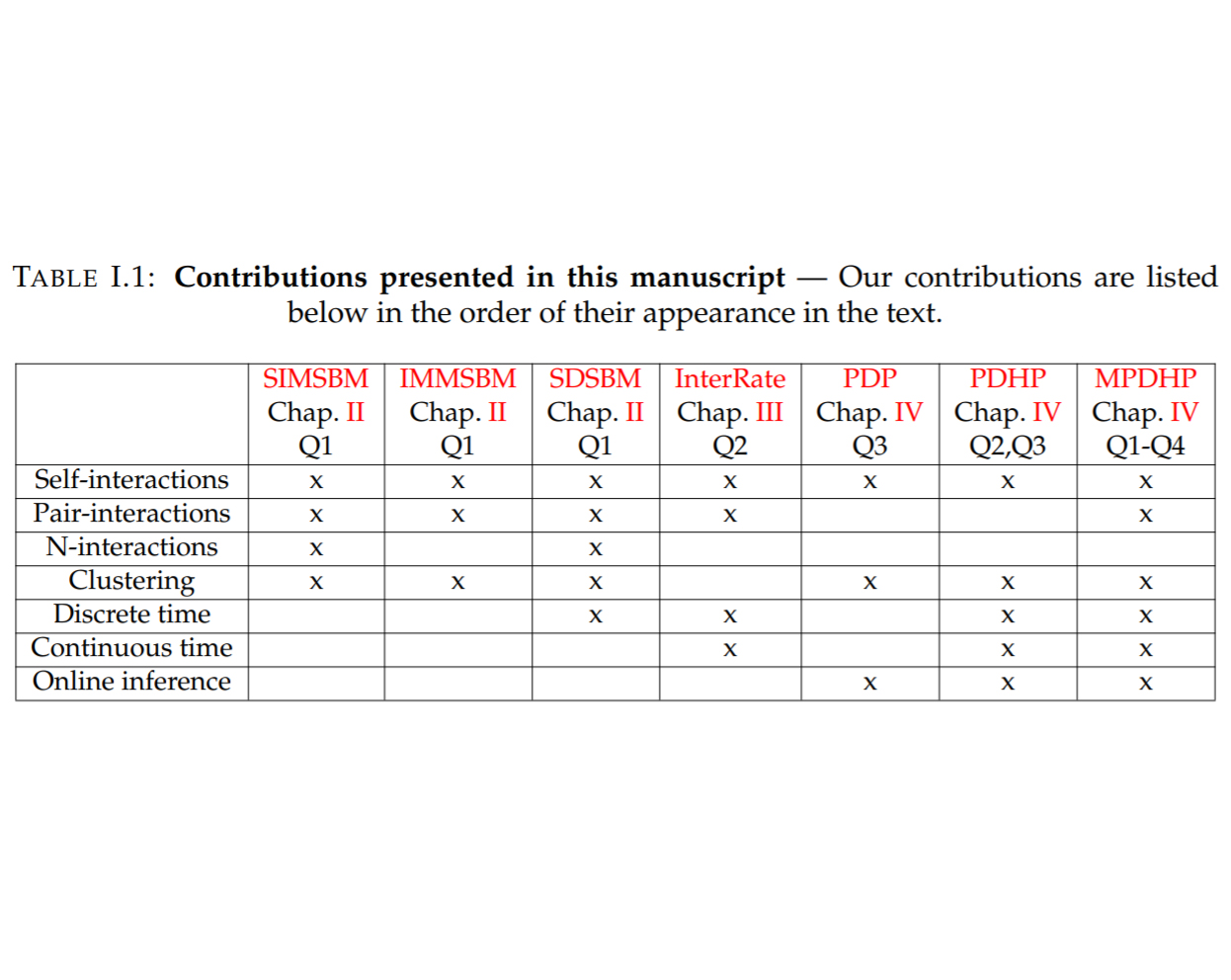
First, we investigate the frequency of such interactions. Building on recent advances in Stochastic Block Modelling, we explore the role of interactions in several social networks. We find that interactions are rare in these datasets.
Then, we wonder how interactions evolve over time; the influence of previously generated data on ulterior data generation processes should not last indefinitely. We model this using dynamic network inference advances on social media datasets. We conclude that interactions are brief and that their influence typically decays in an exponential fashion.
Finally, as an answer to the previous points, we design a framework that jointly models rare and brief interactions. Doing so, we exploit a recent bridge made between Dirichlet processes and Point processes. We improve over this advance and discuss the more general Dirichlet-Point processes and their application to the understanding of interaction processes. We conduct a large-scale application on Reddit, and find that interactions play a minor role in this dataset.
From a broader perspective, our work results in a collection of highly flexible models and in a rethinking of core concepts of machine learning, which both open a range of novel perspectives, either in terms of real-world applications or in terms of technical improvements.
The manuscript