Le Processus Powered Dirichlet-Hawkes comme A Priori Flexible pour Clustering Temporel de Textes
This work is a translation of the Powered Dirichlet-Hawkes Process article (ICDM 2021) for the EGC conference.
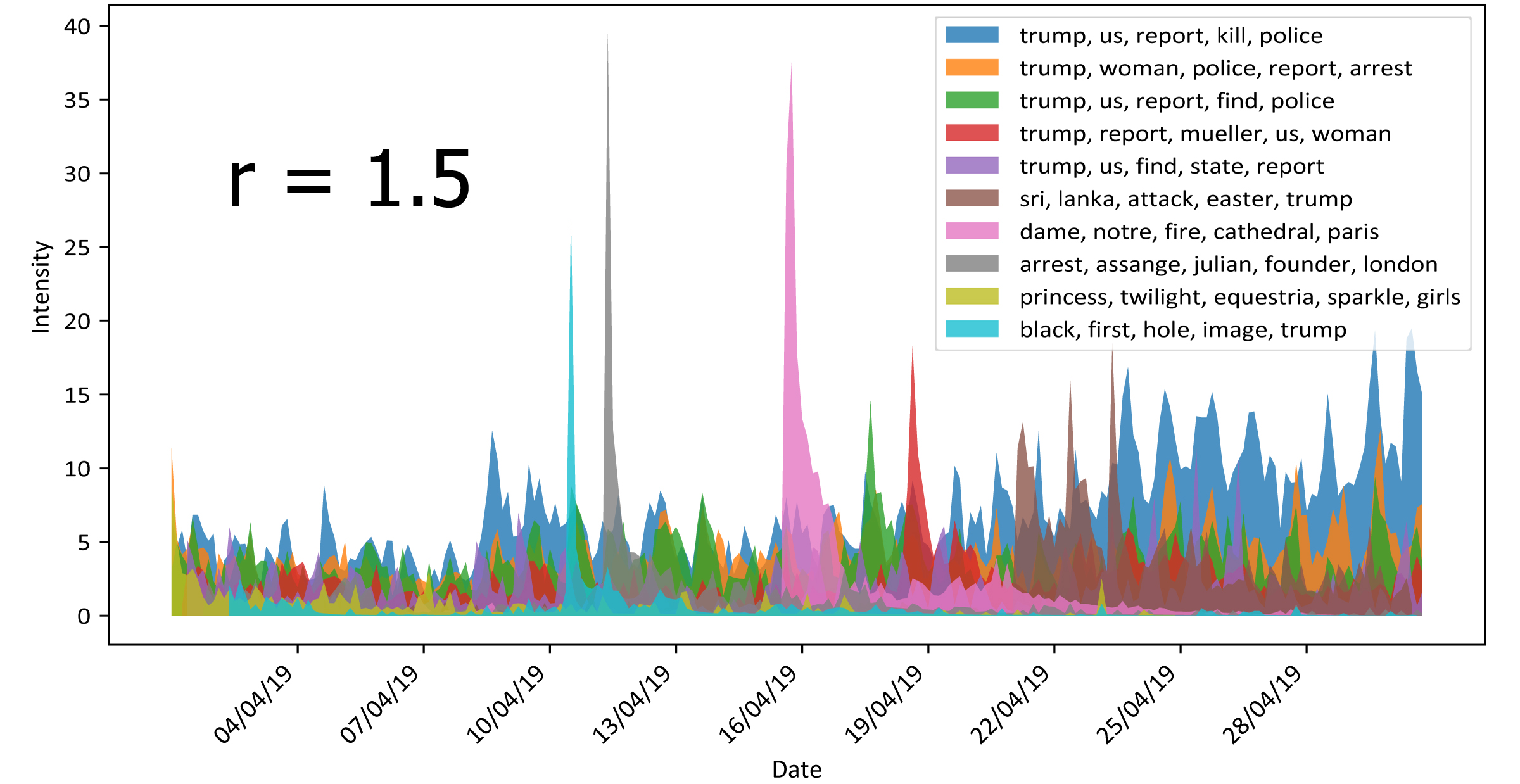
Le contenu textuel d’un document et sa date de publication sont corrélés. Par exemple, une publication scientifique est influencée par les précédents articles cités dans ladite publication. Utiliser cette corrélation permet d’améliorer la compréhension de grands corpus textuel datés. Cependant, cette tâche peut se compliquer lorsque les textes considérés sont courts ou possèdent des vocabulaires similaires. De plus, la corrélation entre texte et date est rarement parfaite.
Nous développons une méthode répondant à ces limites, permettant de créer des clusters de documents en fonction de leur contenu et de leur date : le processus Powered Dirichlet-Hawkes (PDHP). Nous montrons que PDHP présente de meilleures performances que les modèles état de l’art (qu’il généralise) lorsque l’information textuelle ou temporelle est peu informative. Le PDHP se libère également de l’hypothèse d’une corrélation parfaite entre texte et date des documents. Enfin, nous illustrons une possible application sur des données réelles, provenant de Reddit.
Reference:
Le Processus Powered Dirichlet-Hawkes comme A Priori Flexible pour Clustering Temporel de Textes
G. Poux-Médard, J. Velcin, S. Loudcher, Revue des Nouvelles Technologies de l'Information - p.323-330, 2022